
Jako pierwszy temat na blogu chciałbym poruszyć kwestię observability (obserwowalności?) aplikacji webowych. Observability najprościej można wytłumaczyć jako zdolność do monitorowania i analizy wewnętrznego stanu systemu, na podstawie danych z niego wychodzących. Na pierwszy rzut oka mogłoby się wydawać, że nie jest to zbyt istotne – dla biznesu i użytkownika końcowego wewnętrzny stan systemu nie ma znaczenia. Ale czy na pewno tak jest?
Gdy produkcja płonie, a debuggera brak
Każdy, kto wie jak wyglądają webaplikacje od drugiej strony, na pewno się z tym nie zgodzi. Biznesowe oczekiwania w stosunku do takich aplikacji są dzisiaj bardzo wysokie. Poza realizacją wielu funkcjonalności, oczekuje się wysokiej wydajności, oraz niezawodności. Nie chcemy przecież, żeby klient nie mógł zostawić u nas pieniędzy z powodu błędu systemu, prawda? Powoduje to że takie aplikacje robią się bardzo rozbudowane i złożone, a nawet najlepsza architektura nie pomoże gdy klientowi poleci błąd na „prodzie”.
Z racji specyfiki aplikacji webowych nie mamy możliwości szybkiego przedebugowania i wrzucenia poprawki – jako programiści jesteśmy zdani tylko na to, co przygotowaliśmy sobie w przeszłości, aby w przyszłości ułatwić diagnostykę. Czy mamy jakiś stack trace? Czy sam komunikat błędu będzie wystarczający aby zdiagnozować usterkę? A co jeżeli strona się zawiesiła i nie ma komunikatu błędu?
Trzy filary obserwowalności
I tu cała na biało wchodzi obserwowalność. Opiera się ona na trzech filarach:
- Logi
- Podstawowe narzędzie każdego programisty. Niech pierwszy rzuci kamieniem ten, który chociaż raz nie użył logowania w konsoli przy debugowaniu aplikacji. Mogą to być proste tekstowe opisy zdarzeń, albo bardziej rozbudowane i ustrukturyzowane wpisy, zawierające dodatkowe informacje (tzw. Structured logging). Logowane zdarzenia mogą mieć różne poziomy, ponieważ co innego będzie interesowało programistę podczas debugowania, a co innego administratora systemu, który chce sprawdzić treść błędu.
- Metryki
- Używa się ich do numerycznego opisu systemu np. ilość otwartych połączeń, średni czas odpowiedzi. Mogą być pomocne do monitorowania aktualnego stanu aplikacji i konfigurowania alertów z nim związanych.
- Trace
- Mechanizm służący do analizy drogi jaką pokonują żądania w naszym systemie. Przydatne do zrozumienia zależności pomiędzy komponentami, oraz do wykrywania w której konkretnie części systemu występuje problem. Szczególnie istotnie w systemach rozproszonych, gdzie droga requestów może być długa i nieoczywista.
Nie wystarczy jednak logować wszystkiego, jak leci, tylko po to, żeby odhaczyć observability – trzeba mieć na uwadze, po co to robimy. Polecam prosty eksperyment myślowy: czy taki log otrzymany od klienta pomógłby w naprowadzeniu na rozwiązanie problemu? Jeśli nie, to czy niesie ze sobą jakąś istotną informację dla kogoś? Analogicznie z metrykami i trace – używajmy ich do rzeczy, które dają nam istotne informacje.
Filary w praktyce
Implementacja każdego z tych trzech filarów jest bardzo prosta, wystarczy mieć świadomość ich istnienia i charakterystykę każdego z nich. Z pomocą przychodzi nam tutaj standard OpenTelemetry, wraz z zestawem gotowych bibliotek dla różnych języków programowania. Dzięki nim, eksport logów/metryk/trace to raptem kilkanaście linijek w kodzie. Sam standard jest już dość mocno upowszechniony i wspierany przez wiele narzędzi do wizualizacji zebranych danych np. Grafanę.
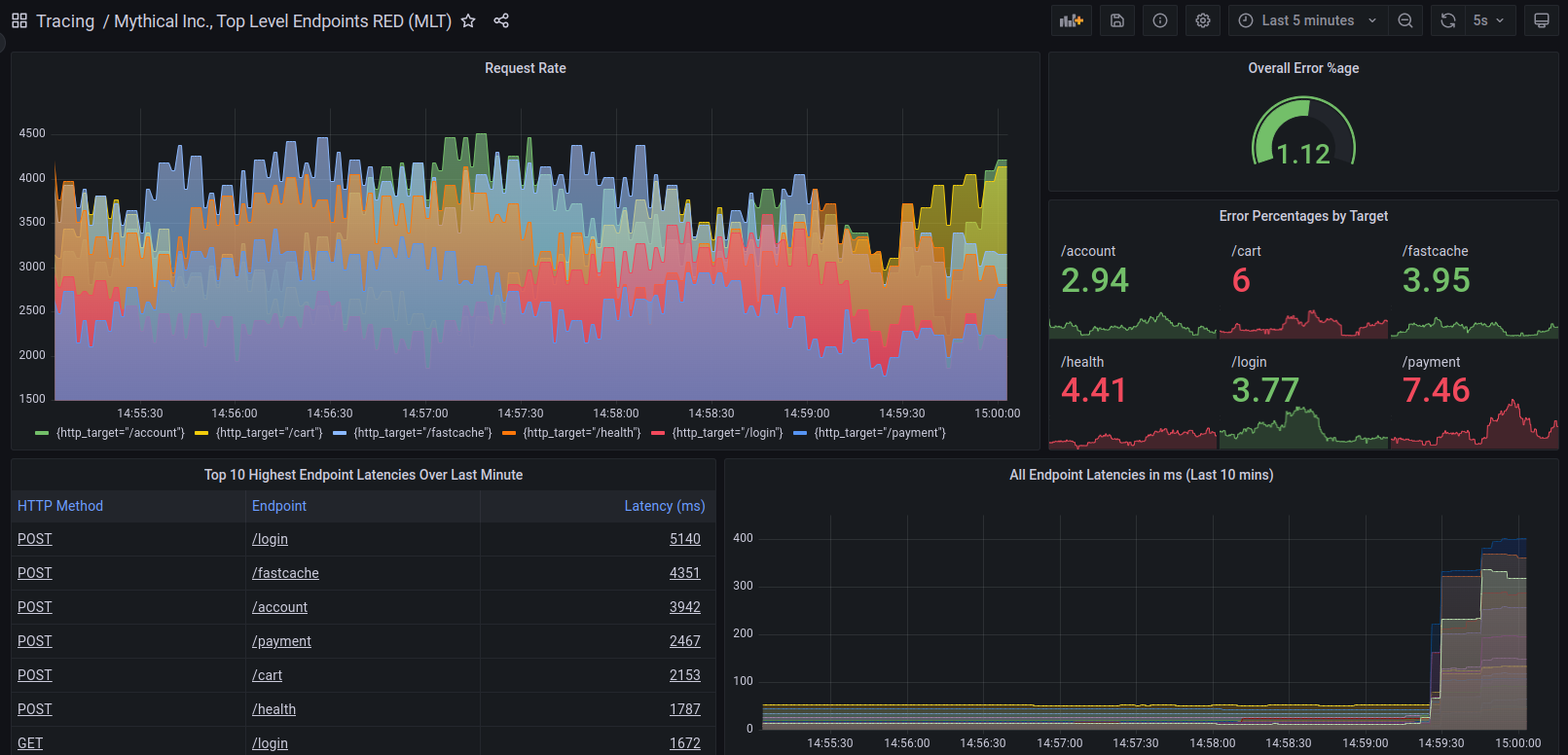
Oczywiście wszystkie opisane tu rzeczy nie ograniczają się tylko do aplikacji webowych, jednak to w nich korzyść z ich używania będzie największa. W większości programów nie ma potrzeby do tak dokładnego monitorowania ich stanu – w prostej aplikacji desktopowej, z której korzysta jeden użytkownik raczej nie będzie się działo zbyt wiele. Zwykłe logowanie i dobra obsługa błędów jest dobrym punktem wyjścia, a do sięgnięcia po metryki lub trace powinien nas skłonić jakiś konkretny powód.
Obserwuj, ucz się, ulepszaj
Podsumowując, observability niesie ze sobą dużo korzyści, pozwalając na lepsze zrozumienie co dzieje się w środku aplikacji. Jest to szczególnie istotne w dużych systemach, gdzie znalezienie powodu błędu jest szczególnie problematyczne, ale każda aplikacja skorzysta z dobrego logowania zdarzeń. Błędy w programach występują i będą występować, ponieważ każdy popełnia błędy i nie jest w stanie przewidzieć wszystkiego, dlatego uważam że każdy sposób ułatwiający radzenie sobie z nimi i pomagający nam zrozumieć jak faktycznie zachowuje się nasz kod jest warta rozważenia.